
As we commence 2021, there is a basic question we are still wrestling with – how do companies OTHER than Google and Amazon adopt voice as a technology and distribute it to users at scale? For participants in the voice ecosystem, this has been the billion dollar question from day one, as we anticipated a massive gold rush in voice akin to what we saw with mobile applications.
In the first phase of the Modern Voice Era, which began with the release of the Amazon Echo in 2014, the assumption was that the platforms offered by Amazon and Google would be the vehicle. But at this point, as third-party skills and actions lose momentum, most of us no longer subscribe to this theory.
Instead, it has been displaced by a new theory: custom, specialized assistants will be the channel to bring third parties into the market. Assistants created by companies such as the BBC, Deutsche Telekom, Pandora and Bank of America will unlock a flood of voice applications. This view has been popularized by Bret Kinsella and VoiceBot, and touted by more agile, less behemothic vendors such as Houndify, SpeechMatics, and Rasa, as well those that build for voice such as RAIN Agency.
But both these approaches are wrong. At least as presently constituted. And so the mantle we have to take up is not to pick a side, but instead figure out how we get unstuck.
Before we get to that though, let’s dig into both models and see how we came to this particular point in the evolution of voice technology.
The Two Giant Rocks
Amazon Alexa and Google Assistant offer amazing capabilities, and it seemed almost obvious at first that they would win out as third parties rushed to develop skills and actions. Wasn’t this exactly analogous to the mobile app stores? And similar to mobile, where in the early days it hardly seemed obvious to me that things like gaming would be viable on such tiny, joystick-free devices, we just sort of assumed that the details around how people would discover and subsequently return to these voice apps would get worked out, if not in the first few months, certainly within a year or two. We also hand-waved away issues with the AI – these pesky problems with recognition would of course be optimized into oblivion within a year or two as Amazon brought on 10,000 or so AI specialists.
But for those of us that are regular users of Alexa, there has not been a significant, tangible improvement in the user experience. If anything, it almost seems to have taken a step back from both a developer’s and user’s perspective. Why is this? Well, part of it is because perhaps the challenges with AI are more intractable than we thought. But I believe the answer is simpler than that, and can be summed up in a single word: privacy.
2018 and 2019 were years marked by a slew of embarrassing headlines for Alexa and Google. A wave of “researchers” exposed a variety of potential faults in the system:
- March 27th, 2018: Amazon has a fix for Alexa’s creepy laughs
- April 25th, 2018: Amazon’s Alexa Hacked To Surreptitiously Record Everything It Hears
- May 25th, 2018: Is Alexa Listening? Amazon Echo Sent Out Recording of Couple’s Conversation
- April 11th, 2019: Thousands of Amazon Workers Listen to Alexa Conversations
- July 11th, 2019: Google Contractors Listen to Recordings of People Using Virtual Assistant
- November 21st, 2019: Security researchers expose new Alexa and Google Home vulnerability
Nevermind that most of these were only theoretical exploits, unlike the widespread, astronomically expensive and harmful intrusions that have taken place on web and mobile. That is, if they were even exploits at all: the case of Alexa laughing, for example, was simply Alexa mistakenly thinking it heard users say ¨Alexa, laugh” (Amazon fixed this annoying behavior by changing the phrase to “Alexa, can you laugh”). What is significant, and is now obvious in retrospect, is that people are more sensitive to being recorded than they are to other forms of privacy intrusion, so even if the exploits are fairly harmless, they get people’s attention in a way that a mobile app which scrapes their personal data and mails it to Russia does not (“that’s just my social security number – but the heavens will catch fire if Vladimir Putin hears me flirting with my wife”).
The fallout? For third parties working with Alexa, we have less access to the raw information from users than we did four years ago, when the Alexa SDK first launched. And without that data, it makes it nearly impossible for developers to build their own models and create the type of experiences that users really want.
And so these platforms stand mute for us, as gray and dull as rocks for developers, in spite of the massive intelligence and innovation that burgeons inside.
The Very Hard Place
Thus alternative emerged: separate one’s fate from Alexa and Google and strike out on your own.
This path holds obvious appeal. It has been done with great success by some well-known and technically proficient brands such as Roku, Mercedes-Benz, and Bank Of America. And there are a host of new technologies emerging to assist developers in building their own assistants: Rasa, HuggingFace, DeepGram, and many more. All promise to put the latest and greatest AI innovation into the hands of mainstream application builders. These technologies are truly amazing and exciting.
However – though I believe in the long-term, and perhaps even the medium-term, these technologies hold significant promise, I do not believe they will bring voice to the masses as they stand today. Why? Again, the answer is simple – they are far too complicated.
Take a look at this page from the Rasa documentation:
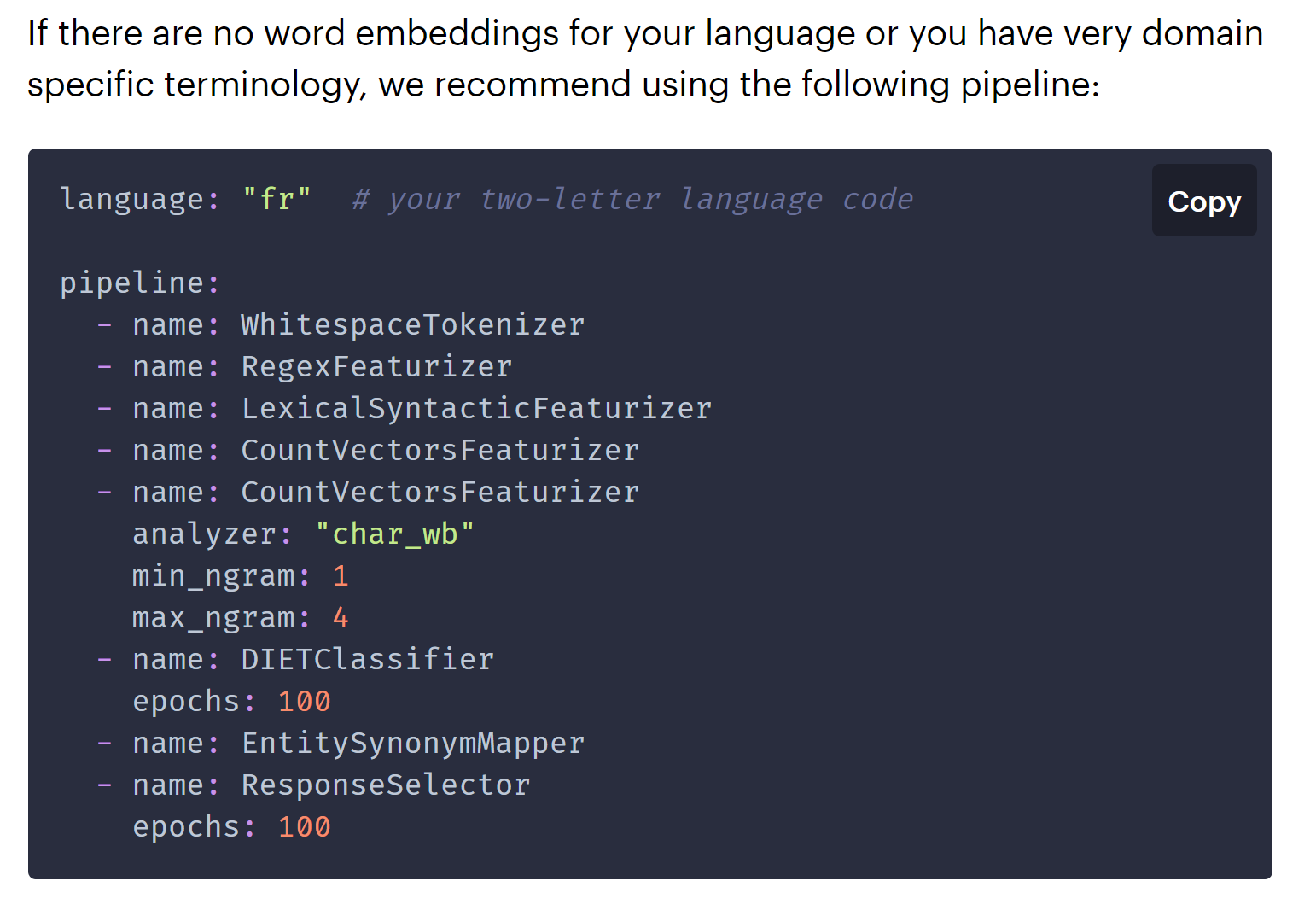
This is the configuration of a Rasa pipeline. For each aspect of this pipeline, there are myriad choices to pick from – they relate to how we break text into words and phrases, how we assign the words and phrases to entities and intents, how to interpret those intents in the context of a larger dialog, and finally, how we decide after we have done all that processing to respond to the user. And I won’t even try to explain succinctly how the TensorFlow neural network fits into this underneath the covers.
Here is a more in-depth explanation of one component in that loop, the DIETClassifier:
Let’s take a look at the DietClassifier and its dependencies. The DIETClassifier depends on two classes of featurizers – dense featurizers and sparse featurizers. Featurization is the process of converting user messages into numerical vectors. The key difference between sparse and dense featurizers is that sparse featurizers compact feature vectors that contain mostly zeroes into a memory efficient structure. If you’d like to learn more about using sparse features, check out this post.
The ConveRTFeaturizer is an example of a dense featurizer that uses the ConveRT model. The LanguageModelFeaturizer is another example of a dense featurizer that uses a pre-trained language model like BERT.
I think you probably get the point: it’s extremely complicated stuff. And if you do understand all that, congratulations! You can probably get a seven-figure job with Amazon or Google. Even then, though, that knowledge is not the key – real-world performance is. You need to pick the right set of components for YOUR use case. Of course, testing and training are essential for this. But even with the best testing tools on the market (ahem, Bespoken, ahem), for many developers and organizations this sort of work will simply be beyond their grasp. And even more likely, beyond their budget.
Slipping Free Via Slender Interfaces
So where does that leave us? Voice at this stage is an interface, not an OS.
This is nothing to be ashamed of; although many of us, myself included, want it to be an operating system, it simply is not there yet. A true AI-based OS would allow device- and bot-makers to:
- Set, and robustly test and train, their own wake words
- Pick their own skills to enable/disable for their specific implementation, from a large list of built-in and third-party components
- Interact with users in complex, multi-step dialogs
- Easily test and train their ASR and NLU for their specific domains and use-cases, using a single, unified model
- Deploy onto devices with minimal processing power, with off-the-shelf hardware components and reference designs
- Work with the myriad other devices and services, local and remote, that users want to interact with.
But on January 1st, 2021, such a thing does not exist. Perhaps things like Alexa Auto are getting close, but I don’t think they are exactly built for the mainstream. With half-a-billion dollars, I think this could be built fairly easily, so please, Google, Amazon, or whoever – get to it! It’s a massive opportunity.
In the meantime, though, voice is not an onramp to generalized assistants. Instead, it is a way to interact via very specific commands that take the place of the work we typically do with our thumbs, remotes, and mouses.
And that is why the best of the “specialized assistants” are from people such as Xfinity and Roku. Their voice search features are well-implemented and satisfying to use. You could call them domain-specific AI (which is what I did last year). Or you could simply call them devices with a voice interface. They enable nothing that one cannot do with a remote or an app – they just provide a way to do it that is more convenient for some use cases (such as entering a long movie name while lying on the couch).
Similarly, smart speakers are better thought of and positioned as content-query devices, not AIs (as was the case during the original launch of the Echo). Thus the rebranding from Google Home to Nest Audio.
The View From The Other Side
None of this, though, is reason to despair. For one, there are new technologies coming on such as GPT-3, which I have intentionally left out of this analysis. I don’t understand it well enough in terms of how it works, and I certainly have not gotten my head around all its possible applications to make predictions about it. Suffice it to say that it is the closest thing to science fiction of any tech I have ever seen, and we will hear a lot about it (and similar innovations) throughout this year and in the coming years.
Moreover, I am going to throw into the same “interface not OS” bucket the entirety of what is happening in customer support. Perhaps it’s a bit unfair because there is some real dialog and real AI being applied here, and we can certainly expect more in 2021. But the interfaces are what are working.
And that’s essential to keep in mind, as we see Amazon and others starting to beat the drums for this next wave, by turns cajoling and bullying IVR implementers to adopt Conversational AI en masse, evangelizing the effortlessness of conversational interfaces to IT managers trapped in phone trees. It sounds great, but there is really no need to over-promise – just offloading the simple tasks typically done by human call center agents onto bots is a big win. There is massive convenience, customer satisfaction, and cost savings to be had there, and none of it requires a PhD. These ambitions may sound modest, but they are exactly the lever we need to get to the other side. Once we arrive, we can all frolic in the silicon meadows with our omniscient bots. This may be as soon as 2024. But it is not going to be 2021, and pretending it is now will only push our future paradise farther away as early adopters become disillusioned and abandon their projects.
So though voice may be stuck at the moment, as a community, I look forward to helping jar it free. I’m confident that our combined grit, expertise and ingenuity will help to take it to the next level; both from the incremental, evolutionary improvement of the tools we already work with as well as the out-of-left-field variety we see with GPT-3.
And, as always, we at Bespoken are here to assist you in delighting your users. Testing, training and monitoring – the pillars of AI development – for whatever the scale of your ambition.
Thank you John. Insightful and sobering read.
Thank you, Cobus!
Very well stated. It would seem to be on the path to the 10 year overnight success phenomena.
Great article John. I do think it looks like it is staled but sometimes it doesn’t feel like because of all the continuing demand.