
We are excited about our new speak command, which allows Alexa developers to interact directly with Alexa from the command-line as if they are talking to it with their voice. It uses the real AVS (Alexa Voice Service), and behaves like a real device.
It is a great complement to our utter and intend commands.
Quick background on our command-line testing tools:
- Speak – use the real Alexa Voice Service (via Text-To-Speech) to talk to your skill
- Utter and intend – generate JSON payloads that mimic what comes from Alexa
Our intend and utter commands use our emulator, while speak uses our new AVS integration. Both are powerful tools for testing Alexa skills. We recommend:
- Using speak for ensuring skill behavior under “real” conditions
- Using utter and intend for deeper testing of skill logic (it provides access to the full skill payload)
Look for our best practices for skill-testing guide soon, with more in-depth guidance on these subjects.
To get setup with the new speak command, first create an account on the Bespoken Dashboard:

Create a new skill or action from your Bespoken Dashboard:
Once there, click on the Virtual Device Manager and create a Virtual Device. This device behaves like a real-live Alexa device, linked to your Alexa account, but with the difference that we interact with it programmatically (instead of talking to it).
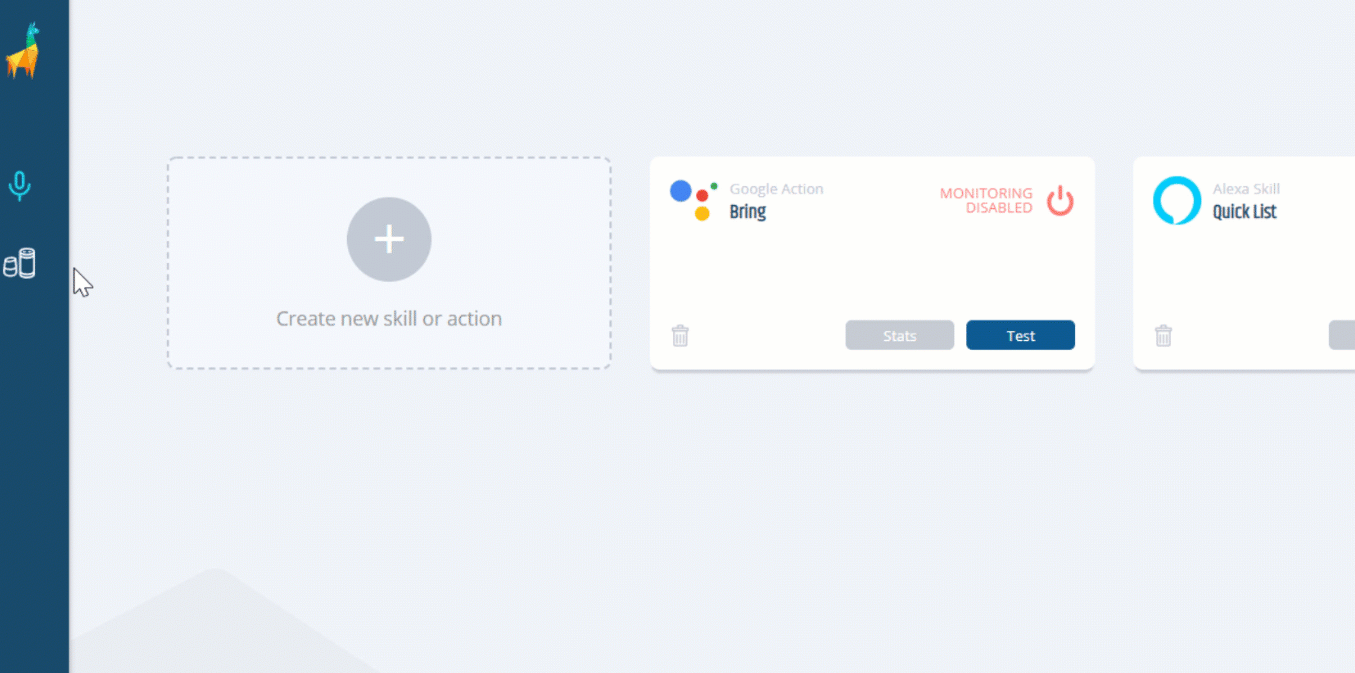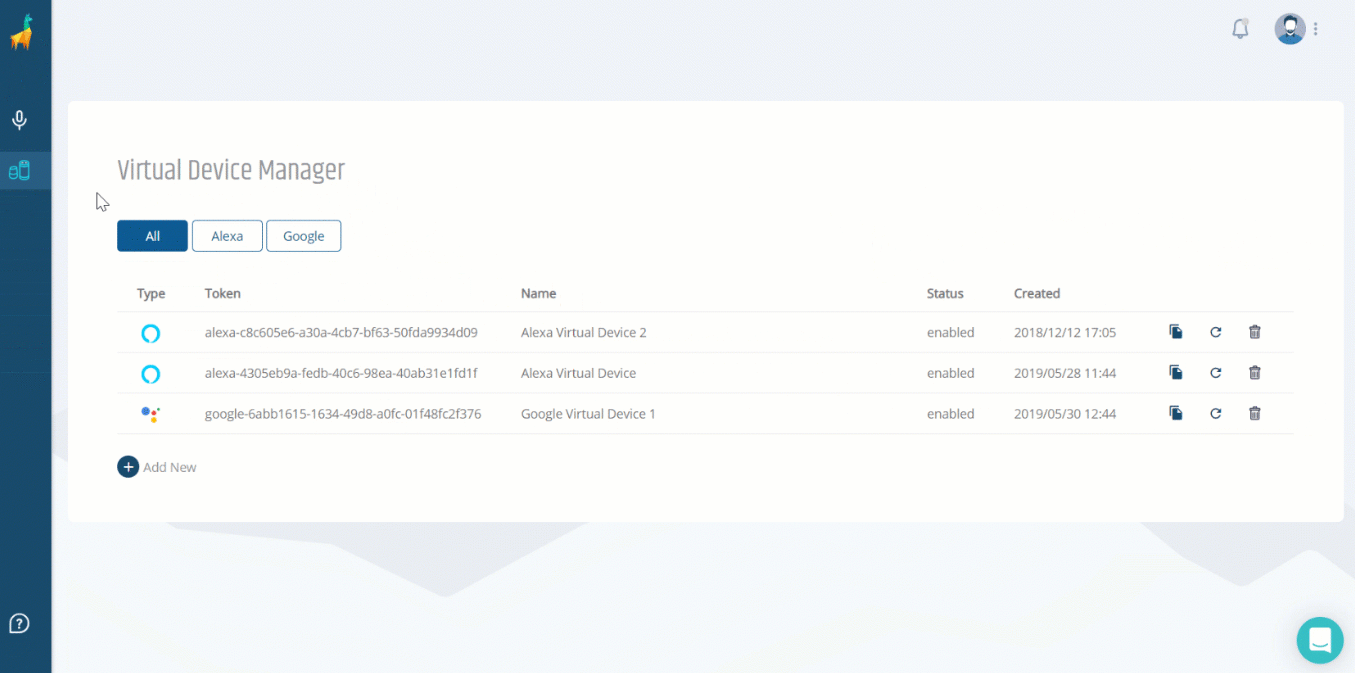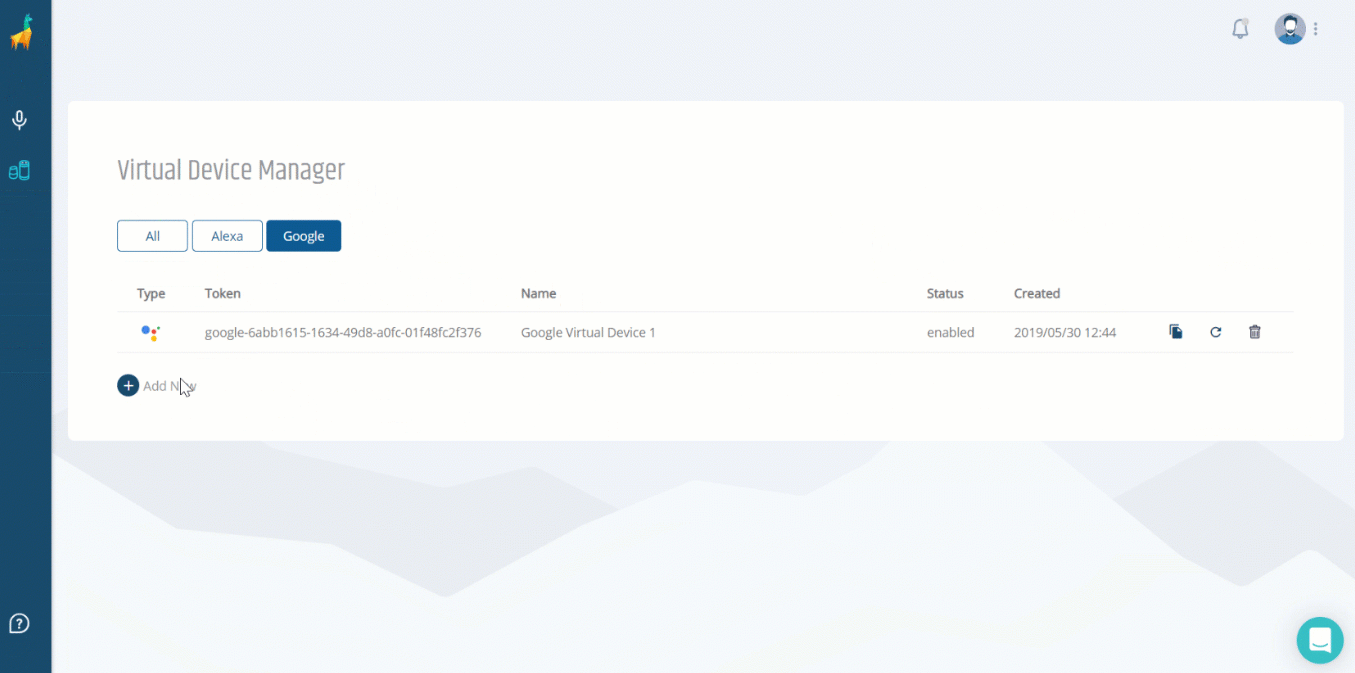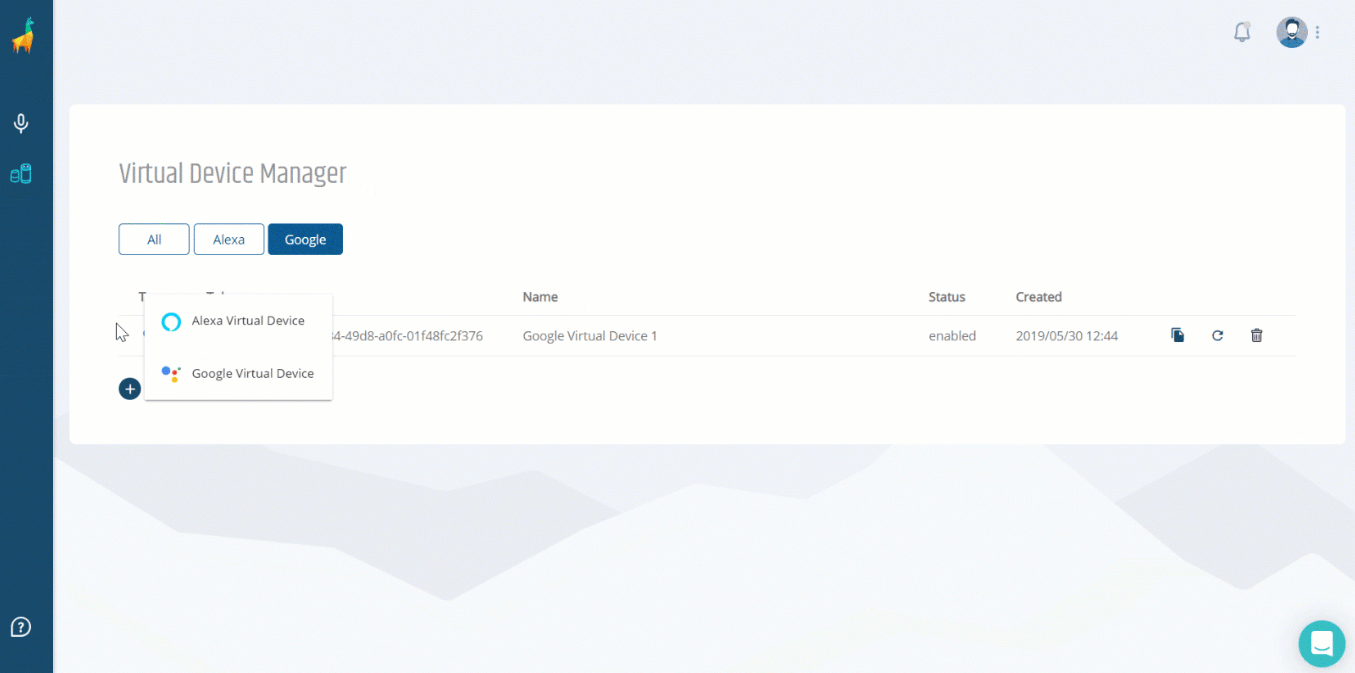
With this token, you can now use your speak command on the command-line!
If you have not already installed the bst command-line, do it now – just enter in a terminal:npm install bespoken-tools -g
The first time you run speak, enter:bst speak --token TOKEN_FROM_VALIDATION_PAGE hi
After you enter the token the first time, it will be saved off to your `.bst/config` file so you will not need to enter it again.

Now try testing your skill – I am going to run it against one of our own, We Study Billionaires:
It is possible to do sequences of interactions, though keep in mind, the skill session behaves similar to a real device – there is a limited time to reply before the session ends. So best to be ready with your next command if performance multi-step interaction (or even put it into a script).
Besides returning a transcript of what Alexa says, card information when present is also displayed:
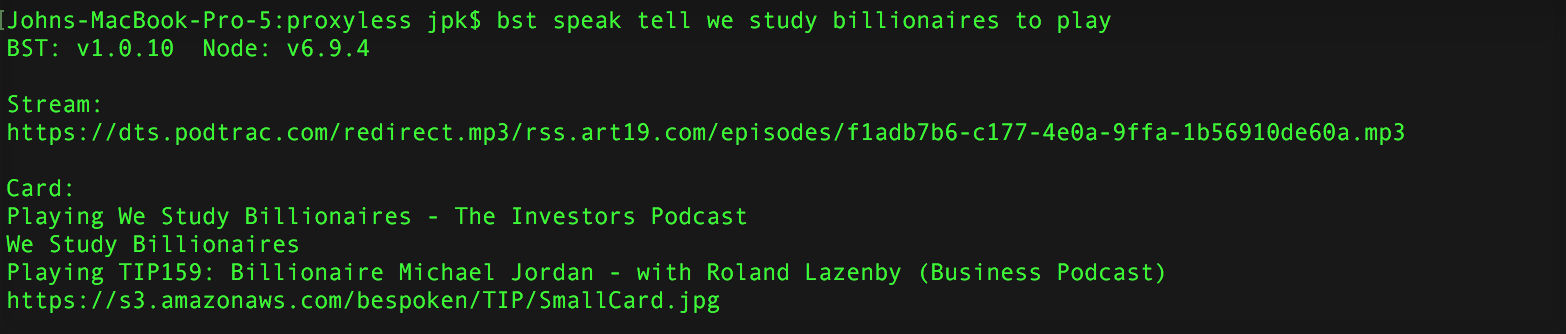
Very cool, right?
That’s all for now – look for more voice testing tools from us, as well as more information on best practices for using them! And feel free to reach me on Slack or Twitter – jpkbst!
[…] The New, Improved speak command for Testing Alexa Skills […]
Outstanding! I see being able to test my alexa skills a lot faster by seeing the response and card info in one quick spot…without the device.
Great work!
Hi John, I am able to use BST SPEAK to initiate Alex skill which activate my local service. However, I can not do a sequence of interaction in the same session. First I use BST SPEAK with the token so that the the token was saved locally. Secondly, I am able to start a new session and talk to my skill by using BST SPEAK ask twenty four. However, after I got the right response from the local service and I type “bst speak yes”, “yes should trigger the next intent in the same session”, I got nothing from my local service. Any insights about what is wrong from what I was doing? Thanks,
Hi Jeremy, I’m sorry you are having this problem. This is actually a known issue, that we have fixed but have not deployed.
I will let you know as soon as it is deployed. In the meantime, if you say “bst speak alexa yes” as opposed to just “bst speak yes”, that should work.
Hope that helps, and thanks for the feedback.
-John
Actually, I need to correct my previous message – we have actually deployed the change. So you should be able to just say “bst speak yes”.
Which version are you using? The update is with version 1.1.1.
If you have not updated, just enter at the command-line “npm install bespoken-tools -g” – then try again. Please let me know if it works for you.
Best, John
Hi John, My BST version is 1.1.1 and node is 8.5.0. I still have this issue. Thank you for the quick reply. -Jeremy
BTW, both bst speak yes and pst speak alexa yes do not work for me.
Hi Bebud – I have replicated the issue. We are looking into this – I will update you as soon as we understand better what is happening.
-John
Hi Bebud, the issue has been resolved. I apologize for the inconvenience. Please let us know if we can help with anything else at all!
Best,
John
[…] it’s extremely useful for ensuring voice app performance, and it goes great with our new bst speak command as well as our Virtual Device SDK. They all rely on the same underlying technology to make testing […]